Breaking Vision Models with Invisible Perturbations


Natacha Bakir
Malware Reverse Engineer & CTI Lead
SC Awards “Woman of Influence” 2025 | Recorded Future Excellence Award 2025 | Eurovision 2025 CTI Lead |
VX-Underground/SentinelOne Malware Research Challenge Finalist
Published: 2026-02-13
Reading time: 3 minutes
Demonstrating Adversarial Examples using ART, ResNet, and CIFAR-10
In this article, we demonstrate a practical adversarial machine learning experiment showing how deep learning vision systems can be fooled by nearly imperceptible perturbations. The full notebook is available on my GitHub repository and reproduces the complete experiment step by step.
The goal of this work is simple: show that a highly accurate image classifier can become unreliable when exposed to adversarial inputs that remain visually indistinguishable to humans.
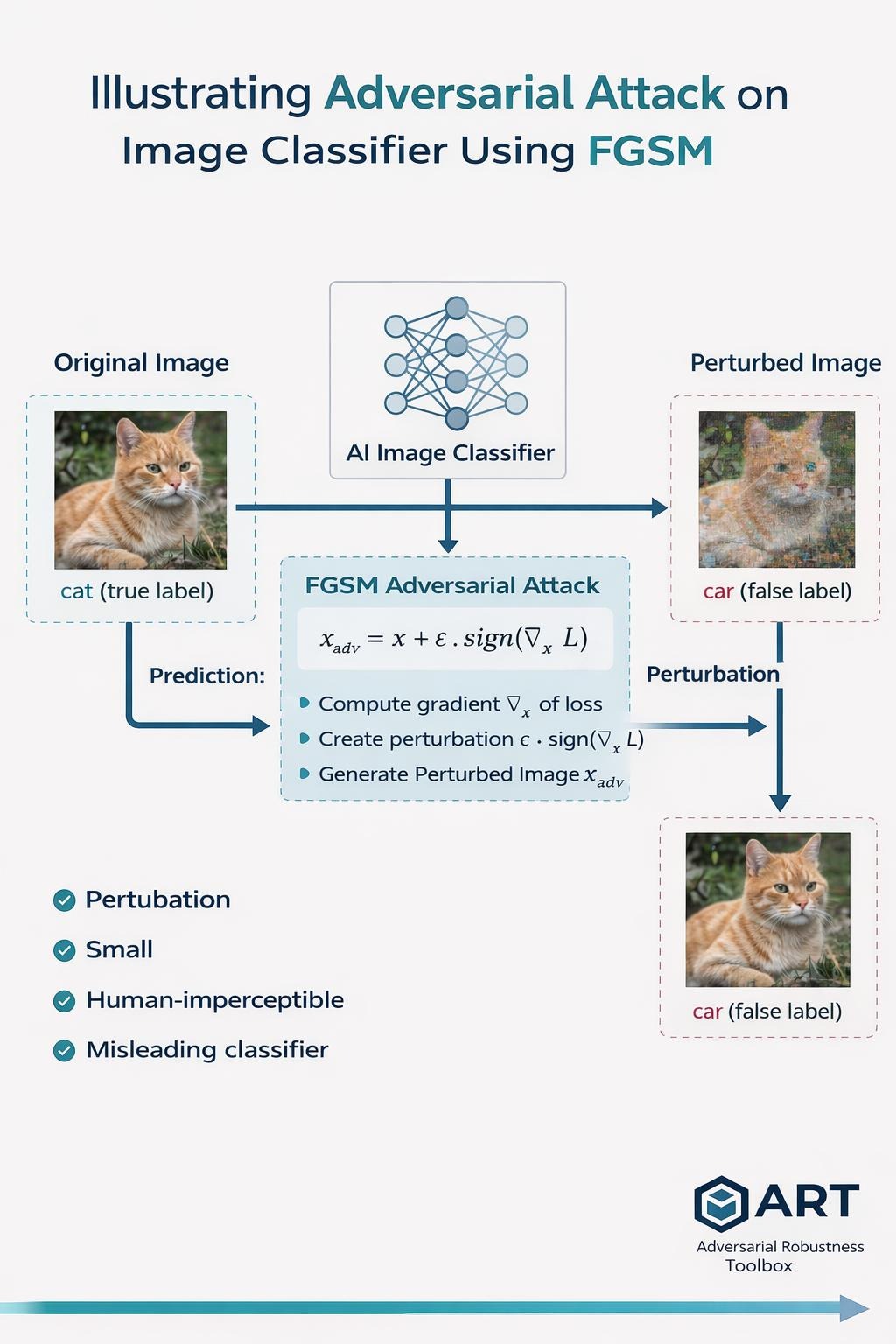
Experiment Overview
The experiment uses:
- The CIFAR-10 image dataset
- A pre-trained ResNet convolutional neural network
- The Adversarial Robustness Toolbox (ART)
- A Fast Gradient Sign Method (FGSM) adversarial attack
The objective is to compare the model’s performance before and after adversarial perturbations are introduced.
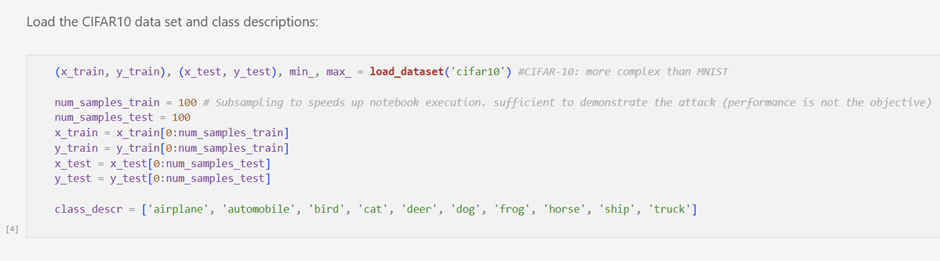
Step 1 — Dataset and Model Preparation
We load the CIFAR-10 dataset, which contains 60,000 color images distributed across ten classes such as airplanes, cats, ships, and automobiles. For demonstration purposes, the notebook uses a reduced subset to speed up execution while preserving the attack behavior.
A pre-trained ResNet model is then loaded. Using a pre-trained model reflects a realistic scenario: attackers target already-deployed systems rather than training new ones.
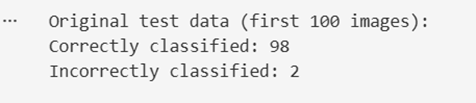
Step 2 — Baseline Model Evaluation
Before launching any attack, the classifier is evaluated on clean test samples to establish a baseline performance reference. In the experiment, the model correctly classifies almost all samples, confirming that the model is functioning as expected prior to adversarial manipulation.

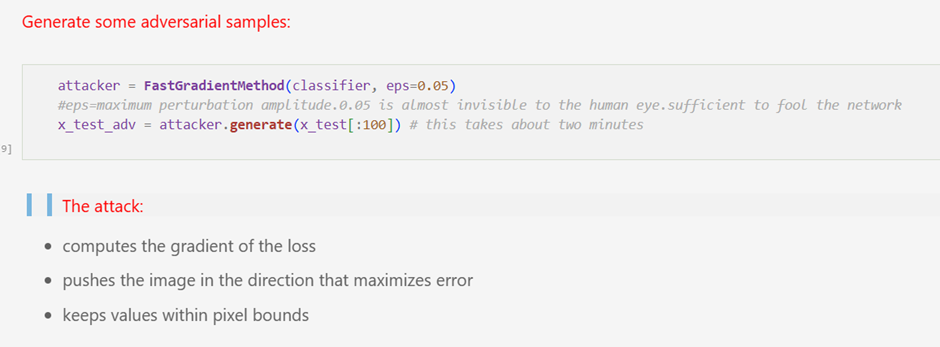
Step 3 — Generating Adversarial Samples
Adversarial examples are generated using the Fast Gradient Sign Method (FGSM), implemented through the Adversarial Robustness Toolbox.
FGSM operates by computing the gradient of the loss with respect to the input image and slightly modifying the pixels in the direction that maximizes classification error:
x_adv = x + ε · sign(∇x L)
The perturbation magnitude ε is intentionally kept small so that the modified image remains visually indistinguishable from the original sample.
Step 4 — Evaluating the Model under Attack
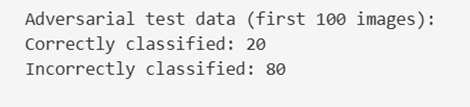
Once adversarial images are generated, the classifier is evaluated again. The results clearly demonstrate a drastic performance degradation, even though the images appear unchanged to human observers.
In this experiment, accuracy drops dramatically, illustrating how fragile even well-trained deep learning models can be when confronted with adversarial inputs.
Step 5 — Visual Inspection of Adversarial Predictions
The final step displays adversarial images alongside the predicted label and the true class. This visual comparison clearly shows the key phenomenon:
The image looks normal to a human
The model prediction changes
The classifier remains highly confident in the wrong prediction
Before

After the attack

Key Takeaways
This experiment highlights several important security insights:
- High accuracy does not imply robustness
- Deep neural networks are highly sensitive to small adversarial perturbations
- Attacks can be fast, automated, and visually undetectable
- AI systems deployed in critical environments must be tested against adversarial threats
Adversarial robustness is therefore not an optional feature but a fundamental requirement for trustworthy AI deployment.
Notebook Access
 |
The full reproducible notebook is available on my GitHub repository: Alphabot42 Alphabot42/AI Security/Practical Adversarial Attacks on Vision Models FGSM Attack on CIFAR 10 using ART |